
Google Chrome innove avec une fonctionnalité révolutionnaire : désormais, les utilisateurs peuvent copier et rechercher du texte directement à partir de PDF scannés. Cette avancée optimise la lisibilité, facilitant l’accès à l’information pour tous. Ne manquez pas cette amélioration significative pour une navigation plus fluide et efficace sur le web !

Google Chrome a récemment lancé une fonctionnalité très attendue qui permet aux utilisateurs de copier du texte à partir de fichiers PDF numérisés. Ce changement améliore considérablement l’expérience des utilisateurs face aux documents scannés, qui ont souvent été problématiques.
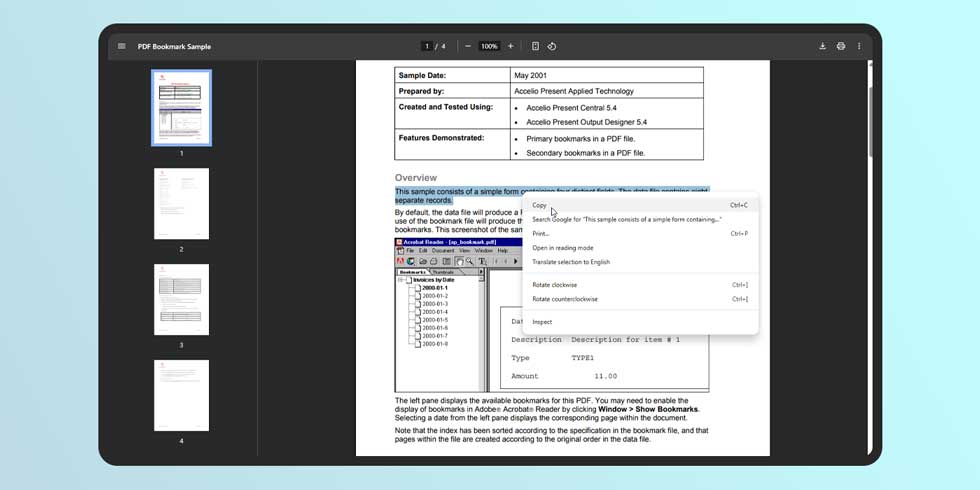
L’un des principaux désagréments rencontrés lors de l’ouverture d’un PDF dans Chrome réside dans le fait que le document original peut avoir été numérisé plutôt que créé numériquement. Dans ce cas, le texte n’est pas visible pour le lecteur PDF de Chrome, ce qui rend impossible la copie et la recherche de texte. Cela limitait l’utilité de Chrome pour l’analyse de contenu dans les documents PDF.
Avec la dernière mise à jour, Google a renforcé son lecteur PDF pour qu’il puisse maintenant distinguer le texte dans les documents scannés. Désormais, les utilisateurs peuvent sélectionner, copier et rechercher du texte en utilisant le raccourci clavier « Ctrl + F ».
Cette fonctionnalité a d’abord été introduite dans la version Beta de Chrome, mais elle est maintenant accessible à un plus grand nombre d’utilisateurs. Cet outil agit comme une ressource pour identifier le texte dans les documents, même ceux qui ont été importés par des méthodes optiques. Les fichiers numériques conservent leur signature de texte, que Chrome pouvait toujours détecter, mais les fichiers scannés n’avaient pas cette signature, les rendant illisibles pour le lecteur PDF de Chrome.
La fonctionnalité fonctionne de la même manière que pour un PDF normal lors de la copie de texte dans Chrome. Il suffit de surligner le texte pour le copier, et la recherche dans la page affichera les résultats correspondant à la phrase entrée. Il n’y a pas de différence notable dans le lecteur d’un document à un autre.
Il était prévisible que Chrome introduise cette fonctionnalité, surtout avec la montée en puissance de Google Lens, qui est devenu un élément central du navigateur. La détection de texte était déjà une fonction présente, mais elle ne semblait pas aussi intégrée que cela.
Fonctionnalités de Chrome pour PDF
Cette nouvelle fonctionnalité renforce également l’attractivité de Google Chrome en tant qu’outil de productivité. Les utilisateurs qui traitent régulièrement des documents scannés, comme des contrats, des factures ou des formulaires, bénéficieront grandement de cette amélioration. En permettant aux utilisateurs de copier et de rechercher du texte, Chrome facilite l’extraction d’informations importantes sans avoir à recourir à des logiciels tiers ou à des étapes supplémentaires.
Les entreprises et les professionnels qui utilisent les PDF scannés comme méthode de documentation apprécieront également cette avancée. Cela leur permettra de gagner du temps et d’améliorer leur efficacité dans la gestion de documents. En effet, l’intégration de cette fonction dans le navigateur le rend accessible et convivial, éliminant ainsi le besoin de solutions complexes.
Impact sur l’utilisation quotidienne
Avec l’augmentation des documents numérisés dans le monde professionnel, la capacité de Google Chrome à traiter ces fichiers de manière efficace est primordiale. Les étudiants, les chercheurs et les professionnels peuvent désormais extraire facilement des citations ou des références à partir de documents scannés, ce qui leur permet d’améliorer la qualité de leurs travaux. Cette fonctionnalité ne se limite pas seulement à la copie de texte ; elle ouvre également la porte à une recherche plus approfondie et à une meilleure compréhension des documents.
Google continue d’améliorer l’accessibilité de ses produits, et cette mise à jour est un exemple parfait de la manière dont la technologie peut simplifier des tâches complexes. Les utilisateurs peuvent maintenant exploiter pleinement le potentiel des documents PDF, augmentant ainsi leur productivité et leur efficacité. Grâce à cette avancée, Google Chrome renforce sa position en tant que navigateur de choix pour les utilisateurs professionnels et académiques.
Conclusion
En somme, la capacité de Google Chrome à traiter le texte dans les PDF scannés représente une avancée majeure pour le navigateur. En rendant le texte accessible dans ces documents, Google ouvre de nouvelles possibilités pour les utilisateurs, leur permettant de naviguer et d’interagir avec le contenu de manière plus fluide et efficace. Pour en savoir plus sur les dernières innovations dans le domaine des PDF, rendez-vous sur Adobe Acrobat.
Qu’est-ce que la nouvelle fonctionnalité de Google Chrome pour les PDF scannés ?
Google Chrome permet désormais aux utilisateurs de copier du texte à partir de PDF scannés, une fonctionnalité longtemps attendue. Cela signifie que le texte devient visible et peut être sélectionné et copié dans le visualiseur de PDF de Chrome.
Comment fonctionne cette fonctionnalité ?
La fonctionnalité fonctionne de la même manière que pour un PDF normal. Les utilisateurs peuvent surligner le texte pour le copier et utiliser « Ctrl + F » pour rechercher des termes dans le document. Il n’y a pas de différence dans le visualiseur entre un document scanné et un document numérique.
Pourquoi cette fonctionnalité est-elle importante ?
Cette fonctionnalité est cruciale car elle améliore l’accessibilité des informations contenues dans des documents scannés, qui étaient auparavant illisibles pour le visualiseur de PDF de Chrome. Cela facilite la recherche et l’utilisation du texte dans des documents numérisés.
Quand cette fonctionnalité a-t-elle été introduite ?
La fonctionnalité a été initialement introduite dans la version Beta de Chrome, mais elle est maintenant disponible pour un plus grand nombre d’utilisateurs, rendant le traitement des PDF scannés beaucoup plus efficace.






{kind=link}
Discussion about this post